Enlyft is a B2B customer acquisition and account intelligence platform—helping sales, marketing, and partner teams prioritize the right accounts with AI-powered signals, custom propensity models, and data enrichment across 42M+ companies, 20K+ technologies, and 300M+ people profiles. Features like Account Fit, Buyer Personas, GenAI Outreach, and Buyer Intent don't run on one-off scripts; they're powered by an agentic framework that orchestrates multi-step workflows, tools, and semantic search at scale.
Agentic AI is having a moment. The real differentiator isn't a bigger model—it's AI that can plan, use tools, and orchestrate workflows without hand-holding at every step. Getting from "a few agents in a notebook" to thousands of executions per day taught us that architecture is the unlock: the right boundaries, communication patterns, and operational habits turn agentic systems from prototypes into platforms.
This article kicks off our tech blog series on building production-ready AI agent systems. We share the architectural principles and patterns that make our framework scalable and maintainable—concepts, diagrams, and trade-offs, no code snippets. If you're curious how we think about orchestration, microservices, and observability behind our framework, read on.
What We Mean by "Agentic" at Scale
Agentic AI here means systems that can operate with a degree of autonomy: they take a goal, reason about it, call tools (APIs, search, databases), and adapt their plan as they go. Unlike a single LLM call that returns one answer, agentic systems run multi-step workflows that may involve several reasoning steps, tool calls, and optional human-in-the-loop checks.
Building at scale means moving from "one agent, one script" to orchestration: many agents, shared tools, consistent observability, and configuration-driven behavior so that product and domain experts can iterate without rewriting code.
The rest of this article is about the architecture that makes that shift possible.
The Evolution: Single Agent → Orchestrated System
Many teams start with a single agent per use case: one for research, one for summarization, one for lead scoring. That’s fine until you have dozens of agents, each with its own tools, prompts, and failure modes. The result is familiar: duplicated logic, inconsistent retries and logging, and operational headaches.
The natural evolution is to introduce an orchestration layer that owns execution, tool routing, and cross-cutting concerns (auth, caching, observability), while individual "agents" become declarative workflows rather than separate codebases.
The following diagram captures that evolution:
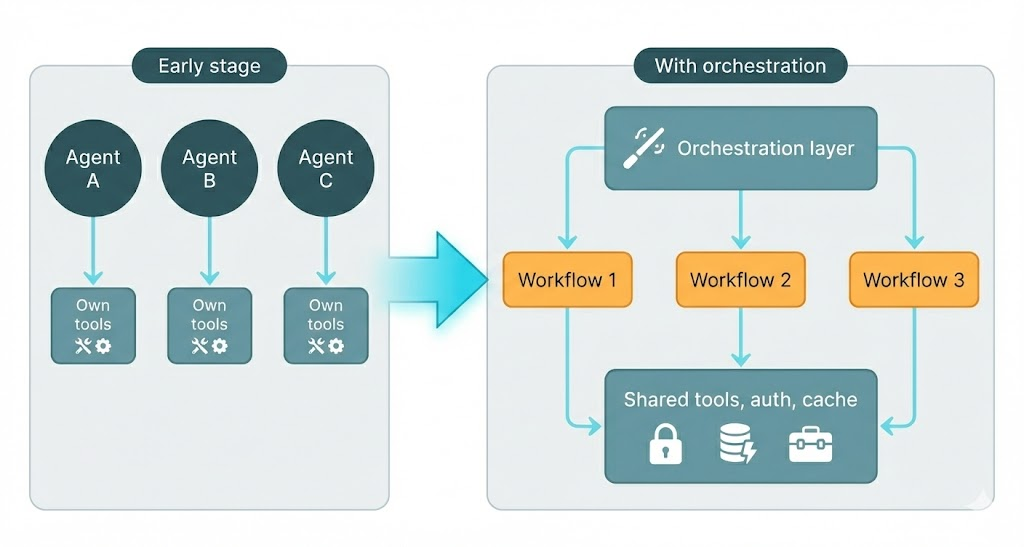
Typical pain points before orchestration:
| Challenge | What happens |
|---|---|
| Duplication | Same retry, logging, and auth logic copy-pasted across agents |
| Inconsistent behavior | Each agent handles errors and timeouts differently |
| Operational complexity | Deploying and debugging requires tracing across many repos or scripts |
| Resource waste | Every agent manages its own connections, caches, and external clients |
A unified orchestration layer centralizes execution, tool integration, and infrastructure so that agents are defined by configuration (e.g. workflows and steps) rather than by separate implementations.
Why Microservices Fit Agent Platforms
Agent systems have natural seams: orchestration, tool execution, vector/embedding workloads, auth, and protocol adapters (e.g. MCP) each have different scaling and technology needs. Microservices align well with these seams.
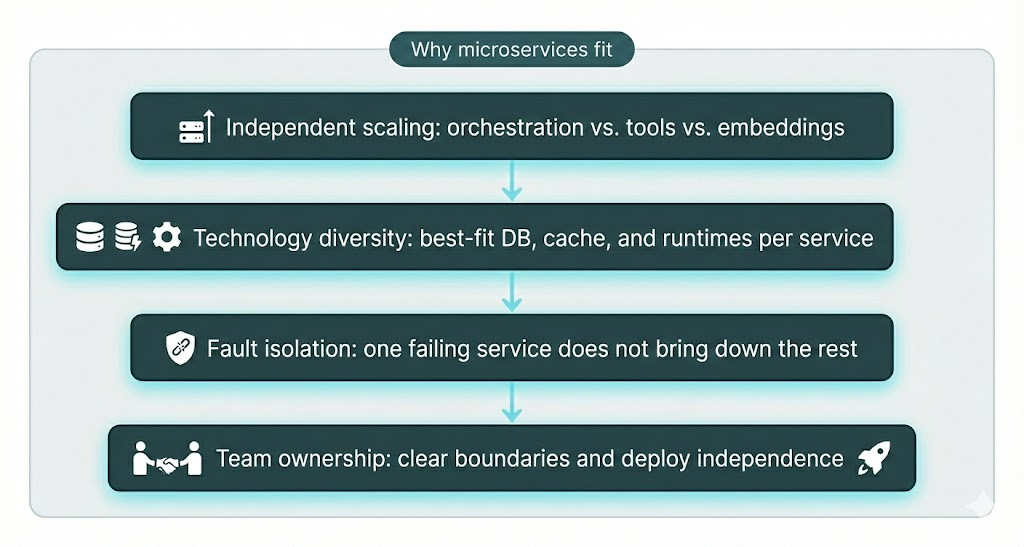
In practice this gives you:
- Independent scaling — Orchestration is often memory- and context-heavy; tool and embedding services may be CPU- or I/O-bound. Each can scale to its own demand.
- Technology diversity — Vector store, general-purpose DB, cache, and external APIs can each use the right stack (e.g. vector DB for embeddings, relational DB for business data).
- Fault isolation — A failing tool or embedding call can be contained with retries and fallbacks without killing the whole orchestration.
- Team autonomy — Clear service boundaries support Own the Outcome: our POD-based teams at Enlyft take full responsibility for their services' results, quality, and timelines, with independent deploys and minimal coordination overhead.
Core Design Principles
Three principles underpin the architecture we use.
1. Separation of Concerns
Each service has one primary job. Conceptual roles (not tied to specific code):
| Role | Responsibility |
|---|---|
| Orchestration / Agents | Run workflows, manage steps, call LLMs, coordinate tool calls |
| Tools | Integrate with external systems: APIs, databases, search, scraping |
| Embeddings / Vectors | Generate embeddings and run semantic search |
| Auth | Validate API keys, manage tenants, sessions |
| Protocol adapter (e.g. MCP) | Expose agent capabilities via a standard protocol |
| Evaluation | Run quality and regression tests on agent behavior |
This separation enables independent development, deployment, and scaling, and keeps ownership clear.
2. API-Driven Communication
All cross-service communication goes over well-defined REST (or RPC) APIs with consistent request/response shapes. Benefits:
- Consistent patterns — Same conventions for errors, timeouts, and versioning across services.
- Testability — Services can be tested in isolation with API mocks.
- Observability — Every call is a clear boundary for tracing and metrics.
No code here—just the principle: treat services as black boxes that communicate only via contracts.
3. Configuration-Driven Behavior
Agent behavior is declarative: workflows and steps are described in configuration (e.g. YAML or JSON), not hard-coded. The runtime interprets these definitions (e.g. "reason step," "call these tools," "loop until condition," "format output").
Choosing the right level of abstraction is less about avoiding "lock-in" and more about choosing your constraints wisely.
Why configuration-driven helps:
- Non-developers can change prompts, steps, and tool choices without code changes.
- Version control applies to agent definitions; you can review and roll back behavior.
- A/B testing is easier when you swap configs instead of code.
- Rapid iteration — Deploy config changes without redeploying services.
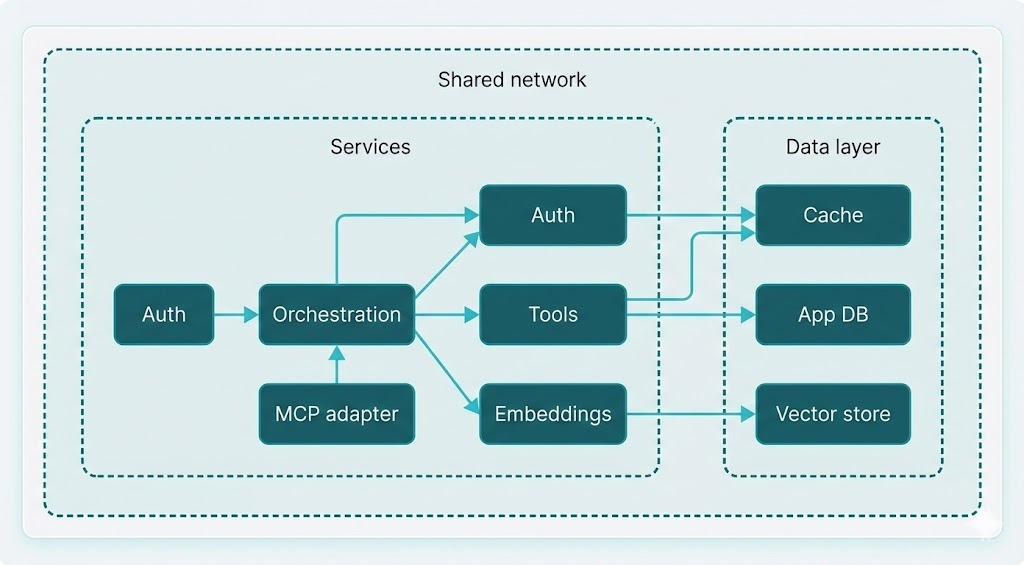
Service Boundaries and Responsibilities
A high-level view of how responsibilities are split across services:
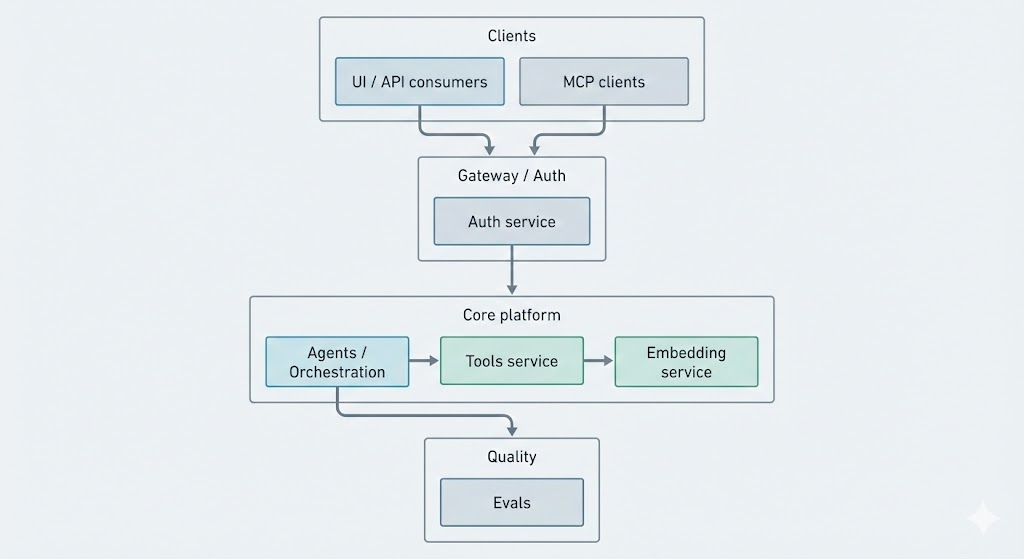
Conceptual responsibilities:
- Orchestration (Agents) — Load workflow definitions, run steps in order, call LLMs, dispatch tool and embedding requests, manage in-memory and cached state for a run.
- Tools — Single place for all external integrations: search, DBs, APIs, scraping. Tools are invoked by the orchestration layer with a consistent interface.
- Embedding service — Generate embeddings and run similarity search (e.g. for RAG or semantic lookup). Keeps vector logic and scaling separate from orchestration.
- Auth — Validate keys, resolve tenants, and optionally cache validation results to reduce load.
- MCP / protocol adapter — Expose the same agent capabilities to external clients via a standard protocol (e.g. Model Context Protocol).
- Evals — Run regression and quality checks on agent outputs (e.g. correctness, relevance, hallucination metrics).
You can think of the orchestration service as the "brain" that decides what to do next, and tools and embeddings as the "hands" that execute those decisions.
How Requests and State Flow
Request flow
A typical execution flows through auth, then orchestration, which may call tools and embeddings as needed:
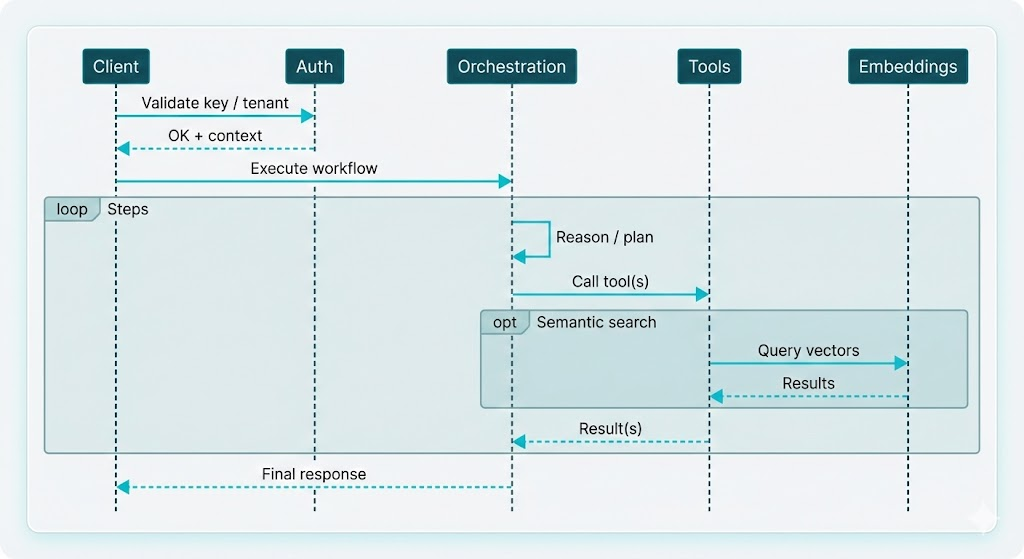
Important idea: orchestration is the single entry point for "run this agent." It is the only component that talks to the LLM and decides when to call tools or embeddings.
State and caching
State flows from in-memory (active run) to cache (reusable step or tool results) to persistence (logs, audit, replay):
Layers in practice:
- In-memory — Current step, inputs, and outputs for an active execution.
- Cache — Step-level or tool-level results keyed by inputs/tenant so repeated work (e.g. same query, same tools) can be reused.
- Persistence — Execution and tool-call logs for debugging, cost attribution, and compliance.
Good cache design (e.g. keying by workflow + step + input hash + tenant) can significantly cut duplicate LLM and tool calls.
Real-World Challenges
Latency
Agent runs add up: multiple LLM calls, tool round-trips, and embedding calls. Mitigations:
- Parallelism — Run independent steps or tool calls in parallel where the workflow allows.
- Caching — Reuse step and tool results for identical or equivalent inputs.
- Connection reuse — Use connection pooling and keep-alive for outbound HTTP and DB connections.
- Async I/O — Use async execution for I/O-bound work to improve throughput.
Cost
LLM and embedding APIs are billed by token and request. Practical levers:
- Token awareness — Track tokens per step and per tenant; use smaller or cheaper models where quality allows.
- Caching — Same as above; fewer repeated calls mean lower cost.
- Visibility — Per-tenant and per-workflow cost reporting so teams can optimize usage.
Error handling and resilience
- Retries with backoff for transient failures (network, rate limits).
- Circuit breakers or fallbacks when a dependency is repeatedly failing.
- Graceful degradation — e.g. return partial results or a clear message when a tool or embedding call fails.
- Dead-letter or failure queues for runs that still fail after retries, for inspection and replay.
Observability
Production agent systems need:
- Distributed tracing — One trace ID across auth → orchestration → tools → embeddings so you can see where time and errors occur.
- Structured logging — JSON logs with execution ID, agent/workflow name, step, and tenant for search and alerting.
- Metrics — Execution count, latency (p50/p95/p99), token usage, cache hit rate, and error rate per workflow and tenant.
- Cost metrics — Token usage and estimated cost per tenant/workflow for billing and optimization.
Infrastructure at a Glance
Conceptually, the system rests on:
- Application databases — Business data (e.g. companies, contacts) and agent/tool execution logs. Often split so that heavy tool queries don't overload the same DB as orchestration.
- Vector store — For embeddings and similarity search; can be a dedicated vector DB or a PostgreSQL extension.
- Cache — In-memory or Redis (or similar) for auth results, step cache, and optionally tool results.
- Containers and networking — Services run as containers; a shared network and health checks define how they discover and depend on each other. Orchestration typically depends on auth, tools, and embeddings being up; evals may run as batch jobs rather than always-on services.
Conclusion and Takeaways
Building production-ready agentic systems is less about the latest model and more about architecture: clear boundaries, contract-based communication, configuration-driven behavior, and operational habits (observability, cost, resilience).
Takeaways:
- Orchestration over scattered agents — A single orchestration layer with shared tools, auth, and caching reduces duplication and operational chaos.
- Microservices match agent boundaries — Orchestration, tools, embeddings, auth, and protocol adapters scale and fail independently.
- Configuration-driven workflows — Declarative agent definitions let product and domain experts iterate without code deploys.
- API-first between services — Well-defined APIs improve testability, observability, and team autonomy.
- Observability and cost from day one — Tracing, structured logs, metrics, and token/cost visibility are essential for production.
Whether you use SDKs, scaffolding, or full-blown frameworks, you're always buying into a set of assumptions. The trade-off is flexibility vs. speed, control vs. productivity, and custom design vs. convention—choose consciously.
About this series
This post is Part 1 of an 11-article series on how we build and run our agentic framework at Enlyft. The series is published on tech.enlyft.com and is designed to be read in order:
| Phase | Articles | What you'll learn |
|---|---|---|
| Foundation | 1–2 | Architecture overview (this post) and how we expose agents via Model Context Protocol (MCP) |
| Core | 3–4 | Declarative orchestration: configuration-driven workflows, step types, and advanced patterns (nested agents, parallel tasks, loops) |
| Extensibility | 5–6 | Tool system (APIs, search, data platform) and vector search / embeddings at scale |
| Enterprise | 7–8 | Authentication & security (multi-tenant, API keys) and observability & monitoring (tracing, logging, cost) |
| Real-world | 9–11 | Integration patterns (how the platform uses the framework), testing & evaluation, and deployment & operations |
We'll share architectural decisions, patterns that work in production, and how our engineering culture—Start Simple, Then Scale; Iterate Fast, Learn Faster; Own the Outcome—shapes the way we build. The full index and reading order will be available on tech.enlyft.com as we publish each article.
What's next
In Part 2 we dive into Model Context Protocol (MCP)—how we expose our agent capabilities to external systems through a standard, discoverable interface so that tools, resources, and prompts can be composed without custom glue code. After that, we'll go deep on orchestration: configuration-driven workflows, step types, and how we keep agent behavior in the hands of product and domain experts.
If you're interested in how we build AI-native B2B intelligence at scale, check out Enlyft's platform and our Engineering blog. We're always looking for engineers who want to own outcomes and ship agentic systems in production—see Careers at Enlyft for open roles.