Introduction
In the world of data engineering, managing complex data pipelines with multiple dependencies, transformations, and validations is a challenging task. Our inhouse data pipeline framework provides a sophisticated solution for data workflows by introducing two fundamental abstractions: ingestion nodes (raw inputs) and transformation nodes (computed outputs).
With built-in caching, explicit dependency tracking, and automated recomputation when inputs or logic change, the framework makes pipelines more reliable, scalable, and easier to operate.
Architecture Overview
The framework is built around a set of core components - ingestion nodes and transformation nodes - supported by infrastructure for managing tables, schemas, file inputs, and metadata manifests.
Core Components
1. Ingestion Nodes: The Foundation of Your Data Pipeline
Ingestion nodes represent the entry points of our data pipeline - raw data from external systems as consumed as Input files. They handle the initial ingestion and normalization of data.
Key Features:
- Automatic Date Resolution: Ingestion nodes automatically determine the latest available data based on file patterns or directory structures. This is particularly helpful while loading the datasets.
- Dual Loading Modes: Support for both raw and normalized data loading. (Normalized tables are tables with a full snapshot of the record, not just incremental).
- Schema Validation: Automatic schema checking and validation during storing the data.
- Schema Evolution & backward compatibility: Every version of the table has got its own schema, which helps in reading the older table even if the schema changes later.
- Incremental Processing: Smart handling of data availability and start dates.
- Caching: Built-in persistence for performance optimization.
Ingestion Node Lifecycle:
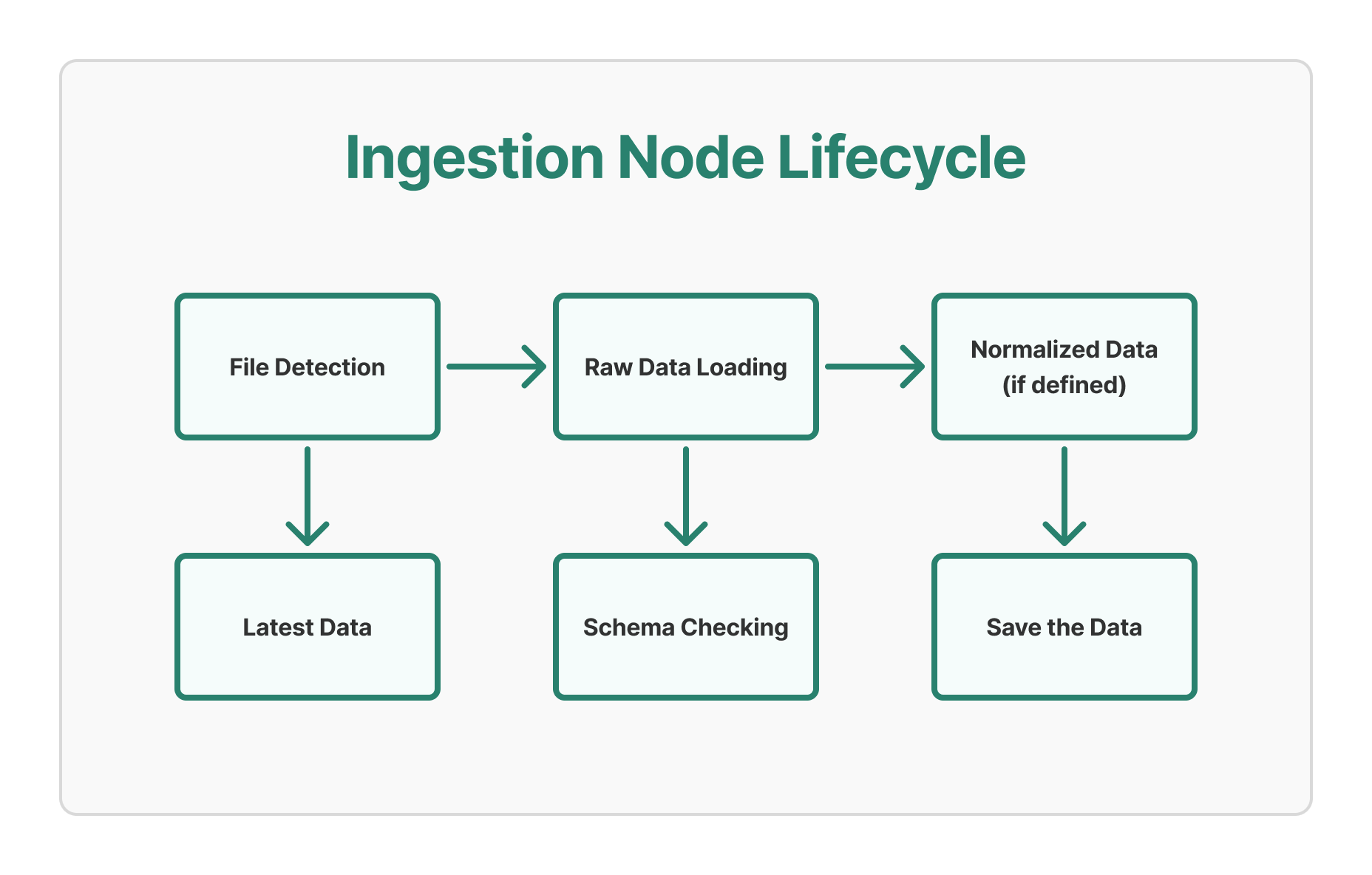
2. Transformation Nodes: Computed Intelligence
Transformation nodes represent computed tables that depend on one or more ingestion nodes or other transformers. They encapsulate business logic, transformations, and complex computations.
Key Features:
- Dependency Management: Automatic resolution of ingestion node and transformer node dependencies.
- Smart Recomputation: Only recomputes when inputs have changed.
- Manifest Tracking: Comprehensive dependency and version tracking.
- Multi-table Support: Can produce multiple related tables in a single computation.
- Environment Awareness: Support for different environments (prod, test, stage).
- Model Integration: Seamless integration with AI/ML models.
- Validation checks: Check data quality after every build and compare with previous builds. The Variations in counts or range of values should be in pre-decided limits
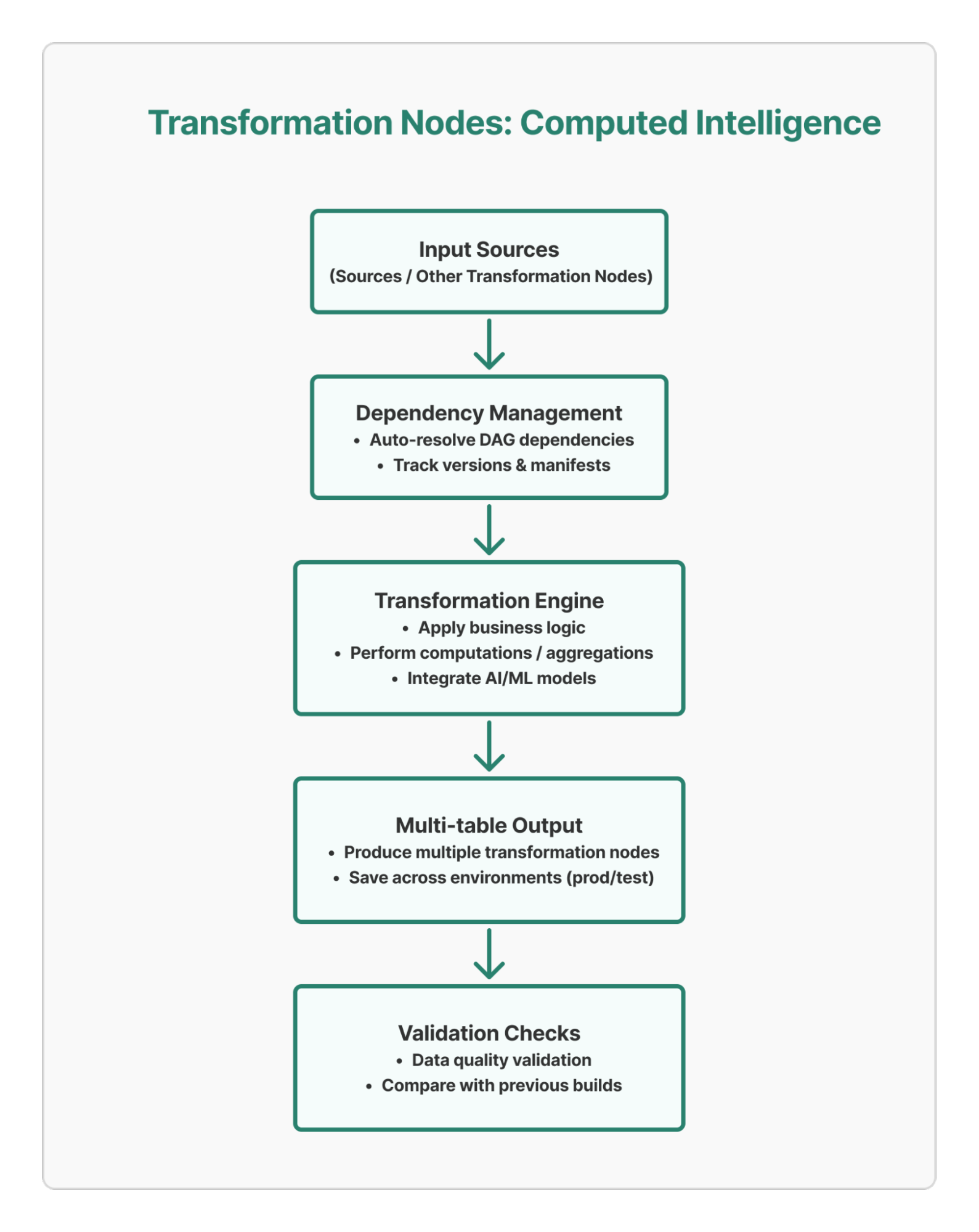
Transformer Processing Flow:
Advanced Features
1. Intelligent Dependency Tracking
The framework uses manifests to track dependencies and detect when recomputation is necessary:
# Example manifest structure
{
"code_version": 1,
"srcs": {
"source_data": "2024-01-15"
},
"ders": {
"enriched_data": {
"code_version": 1,
"srcs": {...}
}
},
"models": {
"ml_classifier": {
"version": "v1.2.3"
}
}
}At runtime, when load function is called on a transformer, it creates a new manifest and compares it with the existing stored one to decide if recomputation is needed.
2. LATEST Processing Strategy
A powerful feature for handling real-time or frequently updated transformations.
3. Environment Management
The framework supports multiple environments with automatic prefixing:
- Production: No prefix
- Test:
TEST_prefix - Stage:
STAGE_prefix
4. Schema Validation and Error Handling
Robust schema management with automatic validation:
Real-World Usage Examples
Example 1: Simple Ingestion Node Definition
INGESTION = {
"data_source": {
"mnt": "raw-data/data_source",
"pattern": "data_source_{d}.csv",
"loader": csv_loader,
"normalizer": data_source_normalizer,
"db": "raw_db"
}
}
# Usage
df_raw = Ingestion("data_source", "2024-01-15")
df = ingestion.load() # Automatically loads and validatesExample 2: Complex Transformer Node with Multiple Dependencies
TRANSFORMER = {
"enriched_data_source": {
"Ingestions": ["data_source1", "data_source2"],
"transformer": ["data_scores:LATEST"],
"models": ["data_classifier"],
"table_patterns": ["enriched_data_source_{d}"],
"compute": enrich_data_source_logic,
"validations": [data_source_validation]
}
}
# Usage
df = Transformer("enriched_data_source", "2024-01-15")
result = transformer.load() # Handles all dependencies automaticallyBenefits and Advantages
- Automatic Dependency Resolution: No need to manually track what depends on what - the framework handles it automatically.
- Intelligent Caching: Only recomputes when necessary, significantly improving performance for large pipelines.
- Robust Error Handling: Built-in schema validation and error recovery mechanisms.
- Environment Flexibility: Easy deployment across different environments with automatic configuration.
- Scalability: Designed to handle complex dependency graphs with hundreds of tables and computations.
- Auditability: Complete manifest tracking provides full lineage and change history.
Best Practices
- Ingestion Node Design:
- Use meaningful patterns for file naming.
- Implement proper normalization logic.
- Handle edge cases in data availability
- Transformation Node Design:
- Keep compute functions focused and testable.
- Use proper exclusion lists for manifest tracking.
- Implement comprehensive validations.
- Performance Optimization:
- Use
.persist()for DataFrames used multiple times. - Leverage the
LATESTprocessing for frequently updated data. - Clear caches when memory becomes an issue.
- Use
Conclusion
This framework provides a robust foundation for building complex data pipelines. By abstracting the complexity of dependency management, caching, and validation into reusable components, it enables data engineers to focus on business logic rather than infrastructure concerns.
The framework's intelligent recomputation logic, combined with comprehensive manifest tracking, ensures that your data pipelines are both efficient and reliable. Whether you are processing daily batch data or building real-time analytics, the framework provides the tools and abstractions needed to build maintainable, scalable data workflows.
Framework Statistics
- Core Classes: 2 (Ingestor, Transformer)
- Supporting Modules: 8+ (Table, Schema, Manifest, File, etc.)
- Supported Environments: 3 (Production, Test, Stage)
- Built-in Validation: Schema validation, data quality checks
- Storage Backend: Snowflake with Spark processing
- Caching Strategy: Multi-level with automatic invalidation
This framework represents a mature approach to data pipeline orchestration, combining the flexibility needed for complex business logic with the reliability required for production data systems.